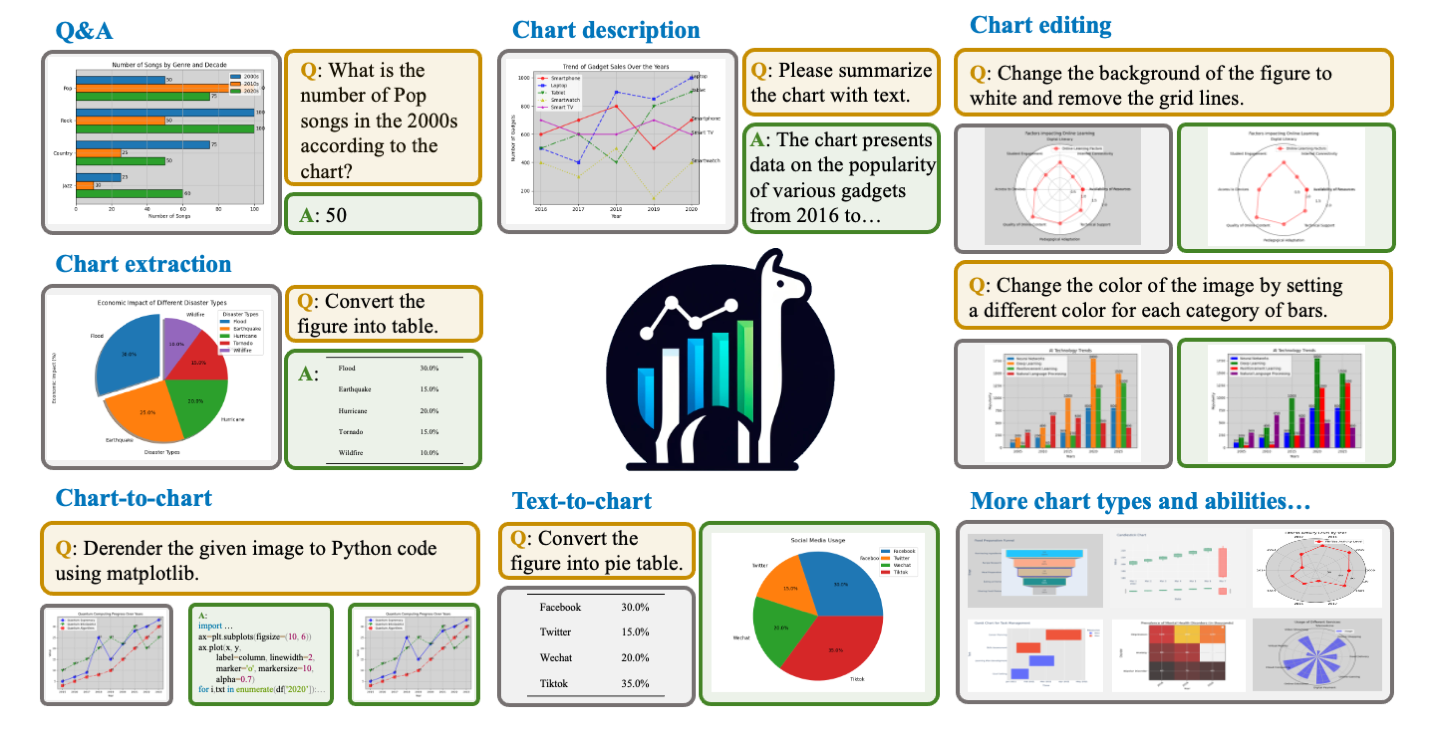
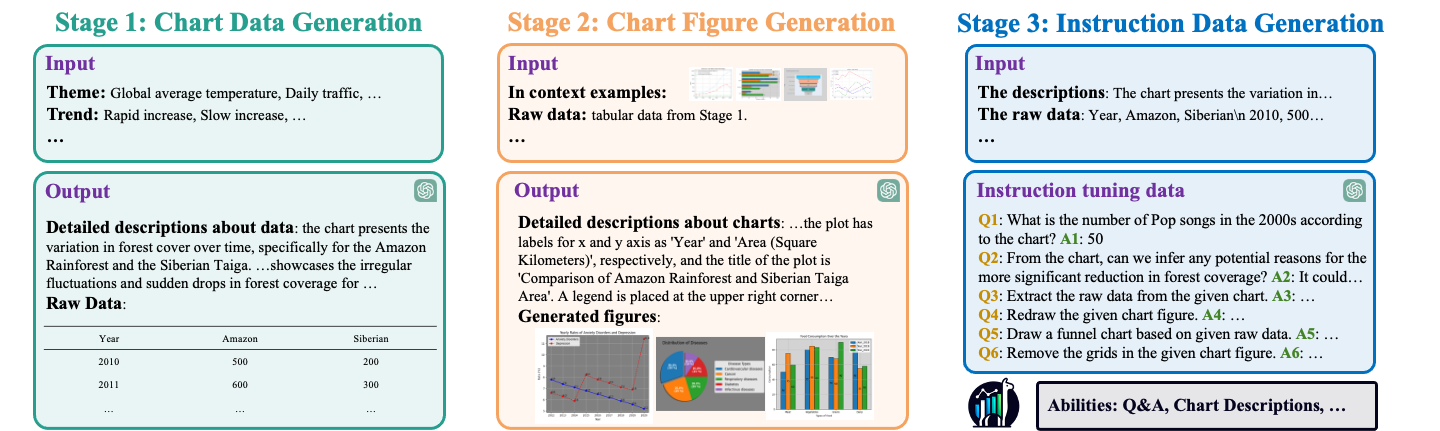
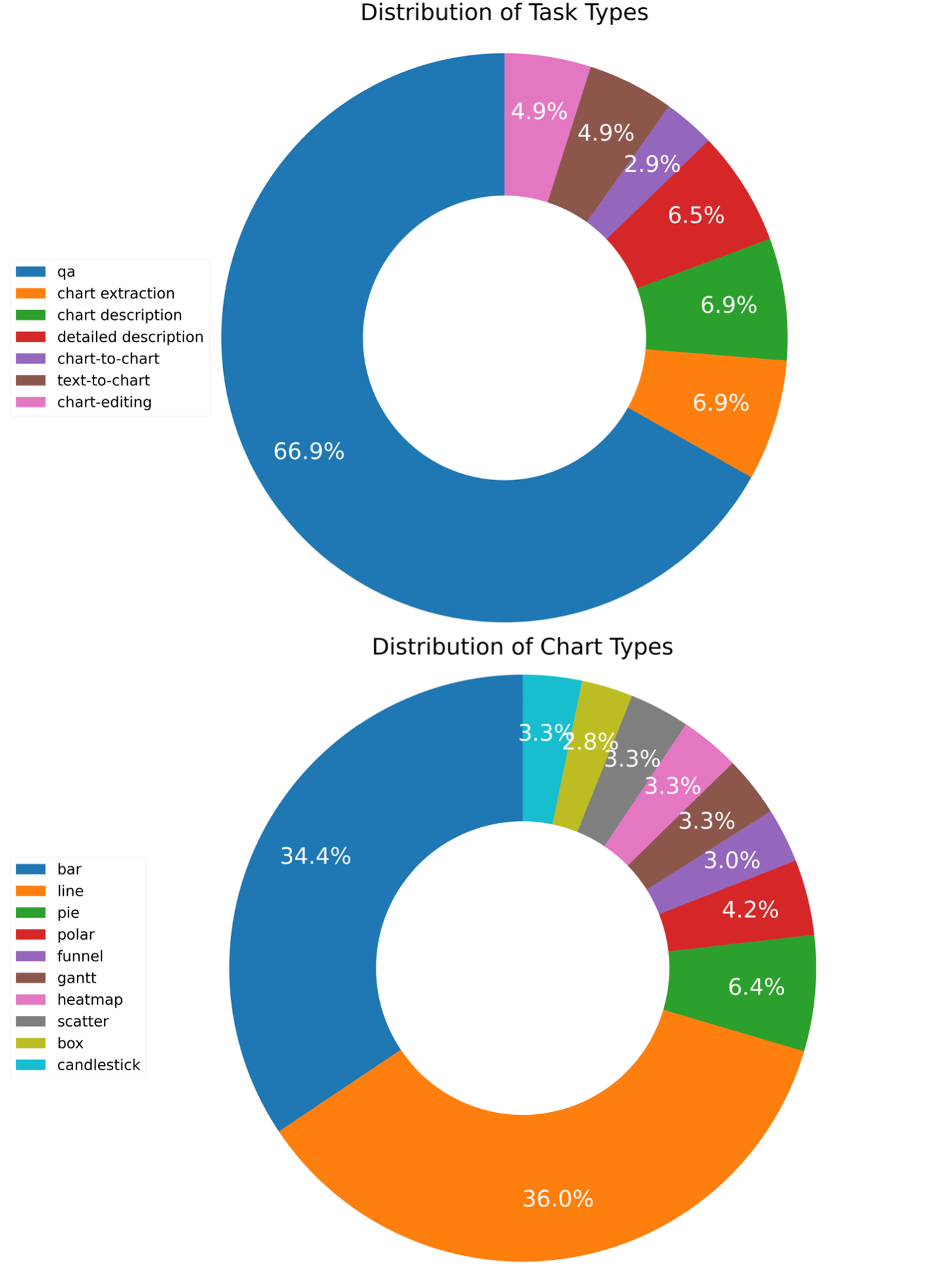
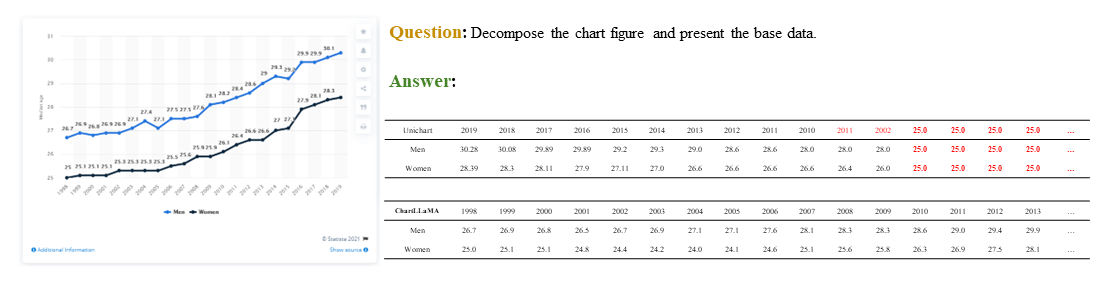
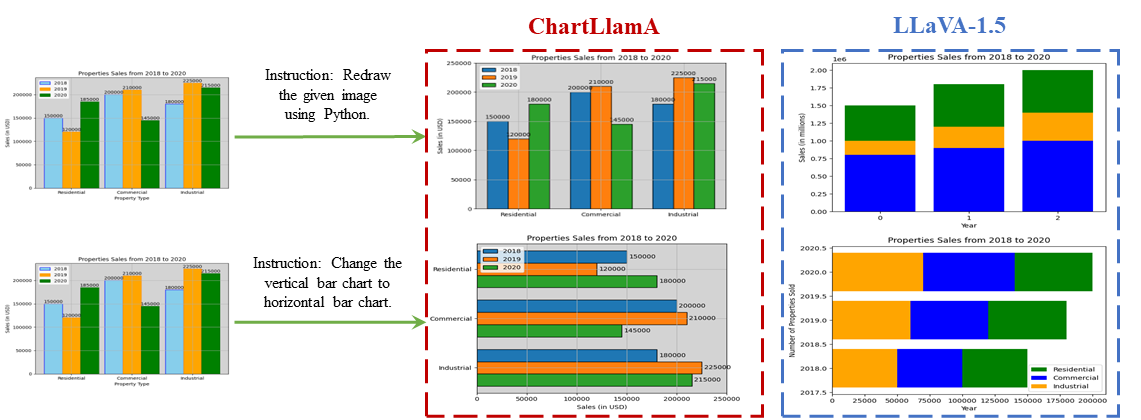
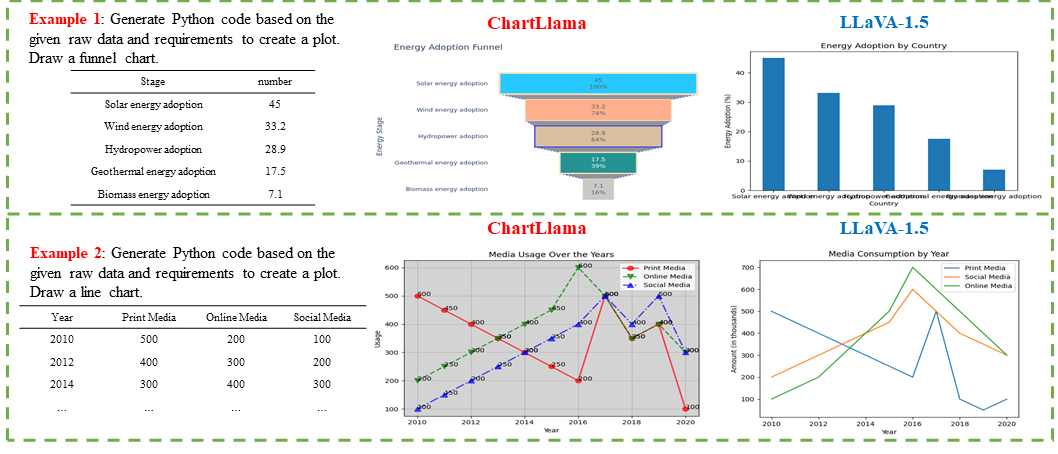
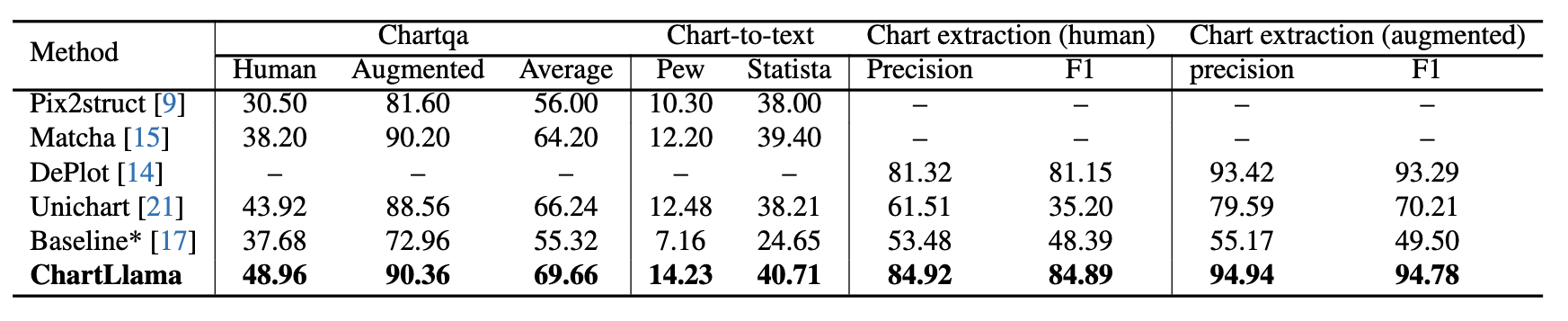
Multi-modal large language models have demonstrated impressive performances on most vision-language tasks. However, the model generally lacks the understanding capabilities for specific domain data, particularly when it comes to interpreting chart figures. This is mainly due to the lack of relevant multi-modal instruction tuning datasets. In this article, we create a high-quality instruction-tuning dataset leveraging GPT-4. We develop a multi-step data generation process in which different steps are responsible for generating tabular data, creating chart figures, and designing instruction tuning data separately. Our method's flexibility enables us to generate diverse, high-quality instruction-tuning data consistently and efficiently while maintaining a low resource expenditure. Additionally, it allows us to incorporate a wider variety of chart and task types not yet featured in existing datasets. Next, we introduce ChartLlama, a multi-modal large language model that we've trained using our created dataset. ChartLlama outperforms all prior methods in ChartQA, Chart-to-text, and Chart-extraction evaluation benchmarks. Additionally, ChartLlama significantly improves upon the baseline in our specially compiled chart dataset, which includes new chart and task types. The results of ChartLlama confirm the value and huge potential of our proposed data generation method in enhancing chart comprehension.



@misc{han2023chartllama,
title={ChartLlama: A Multimodal LLM for Chart Understanding and Generation},
author={Yucheng Han and Chi Zhang and Xin Chen and Xu Yang and Zhibin Wang and Gang Yu and Bin Fu and Hanwang Zhang},
year={2023},
eprint={2311.16483},
archivePrefix={arXiv},
primaryClass={cs.CV}
}